

Current Research Projects
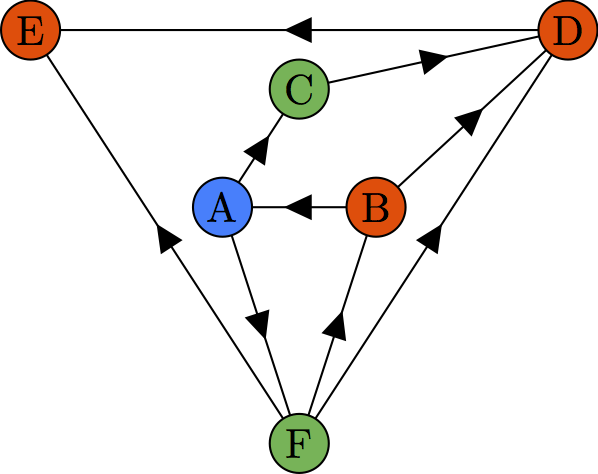 Graph Bandits, 2013 - present
Graph Bandits, 2013 - present
with Gergely Neu, Tomáš Kocák, Shipra Agrawal, Rémi Munos, Alexandra Carpentier, Branislav Kveton, Zheng Wen
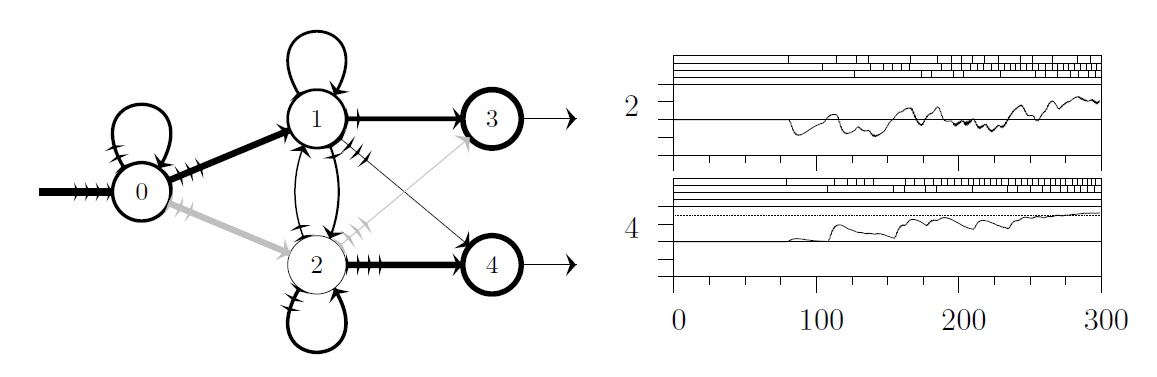
Bandit problems are online decision-making problems where the only feedback given to the learner is a (noisy) reward of the chosen decision. In early sequential decision-making research, we treated each of the decisions independently. While this is enough when the number of actions is very small, it becomes impractical (both theoretically and in practice) when the set of potential actions comprises larger sets, such as a set of movies or products in a recommender system. The minimax regret guarantees scale as Θ(√NT) where N is the number of actions and T is the time horizon. If N happens to be large (such as the number of movies that is in millions), these guarantees are weak. Luckily, the problems become easier if there is efficient information sharing between the actions. For graphs structure, We study the benefits of homophily (similar actions give similar rewards) under the name spectral bandits, side information (well-informed bandits), and influence maximization (IM bandits). In the algorithms, we take advantage of these similarities in order to (provably) learn faster. With respect to the guarantees my colleagues and I derived, we replaced N (number of actions = number of nodes in a graph) with some graph-dependent quantity, possibly smaller than N if the graph structure is helpful.
[ICML 2014] [AAAI 2014] [NIPS 2014] [NIPS 2014] [ICML 2015] [AISTATS 2016] [ENS Cachan 2016] [NIPS 2017]
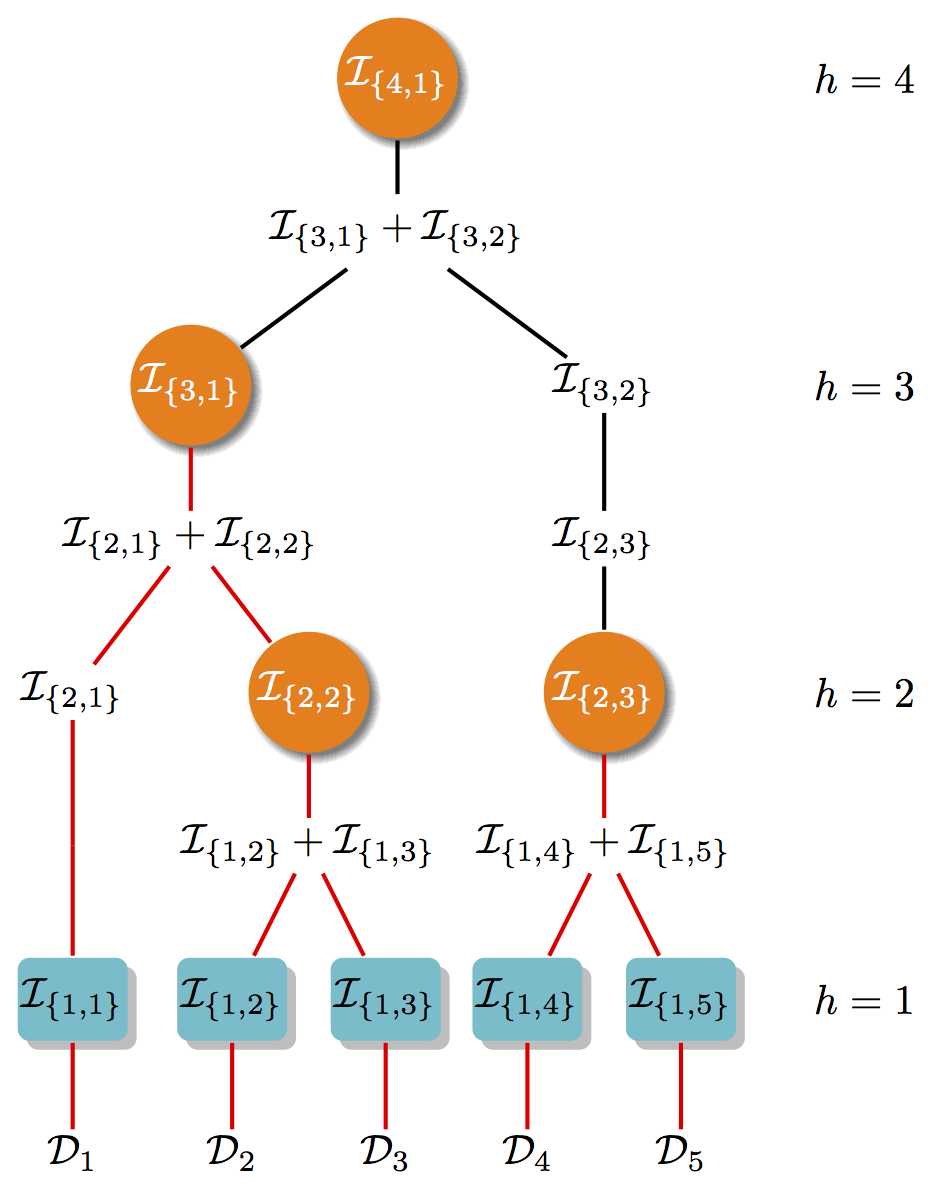 SQUEAK: Online sparsification of kernels and graphs , 2009 - 2018
SQUEAK: Online sparsification of kernels and graphs , 2009 - 2018
with Daniele Calandriello, Alessandro Lazaric, Yiannis Koutis
My PhD thesis ended with an open direction, whether efficient spectral sparsifiers can fuel online graph-learning methods to make online learning with similarities even possible, i.e., with guaranteed performance and non-increasing time-step complexity. In the offline case, this was done already by Spielman et. al (2004). The difficulty of the online case is that we need to deal with the relevance of the data that we have not seen yet. For the problem of spectral approximation in a RKHS, we introduce the first dictionary-learning streaming algorithm that operates in a single-pass over the dataset. Previous results (Alaoui and Mahoney, 2015; and Bach 2013) had either a quadratic-time complexity, or a space complexity that scaled with the coherence of the dataset, a quantity always larger than the effective dimension. Prior methods have also two major drawbacks: (1) they require multiple passes over the data or alternatively random access to the dataset, and (2) they have inherent bottlenecks that make it difficult to parallelize them. We introduce a new single-pass streaming RLS sampling approach that sequentially constructs the dictionary, where each step compares a new sample only with the current intermediate dictionary and not all past samples. We prove that the size of all intermediate dictionaries scales only with the effective dimension of the dataset, and therefore guarantee a per-step time and space complexity independent from the number of samples. This reduces the overall time required to construct provably accurate dictionaries from quadratic to near-linear, or even logarithmic when parallelized. Finally, for many non-parametric learning problems (e.g., K-PCA, graph SSL, online kernel learning) we show that we can use the generated dictionaries to compute approximate solutions in near-linear that are both provably accurate and empirically competitive.
[UAI 2016] [AISTATS 2017] [ICML 2017] [NIPS 2017] [arXiv:1609.03769] [arXiv:1601.05675]
-
Sample efficient Monte-Carlo tree search: TrailBlazer, SmoothCruiser, StoSOO, POO, and OOB, 2011 - now
 with Jean-Bastien Grill,
Rémi Munos,
Alexandra Carpentier
with Jean-Bastien Grill,
Rémi Munos,
Alexandra Carpentier
Monte-Carlo planning and Monte-Carlo tree search has been popularized in the game of computer Go (Coulom 2007, Gelly 2006, Silver 2016) and shown impressive performance in many other high dimensional control and game problems (Browne 2012). The empirical success of UCT on one side but the absence of performance guarantees for it on the other, incited research on similar but theoretically founded algorithms. Our first contribution are generic black-box function optimizers for extremely difficult functions (extremely nonsmooth, no derivatives…) with guarantees with main application to hyper-parameter tuning. The second set of contributions in planning. The first example is TrailBlazer, adaptive planning algorithm in MDPs (Markov decision process).
[ICML 2013] [CEC 2014] [ICML 2015] [NIPS 2015] [NIPS 2016]
-
 Adaptive structural sampling, 2013-2020
Adaptive structural sampling, 2013-2020
with Alexandra Carpentier, Andrea Locatelli, Akram Erraqabi, Alessandro Lazaric, Rémi Bardenet, Guillaume Gautier
Many of the sequential problems require adaptive sampling in some particular way. One example is using learning to improve rejection rate in rejection sampling by learning the proposal. [Erraqabi et al. ICML 2015]. Another one is sampling with two contradictory objectives such as when we have to trade off reward and regret [Erraqabi et al. AISTATS 2016]. Other examples include extreme [Carpentier and Valko, NIPS 2014] and infinitely many-arm bandits. [Carpentier and Valko, ICML 2015]. Finally, we have worked on an efficient sampling of determinantal point processes [Gautier et al, ICML 2016] and applying them to diverse recommendation and numerical integration.
[ICML 2015] [ICML 2016] [AISTATS 2017] [ICML 2017]
Recent Research Projects
-
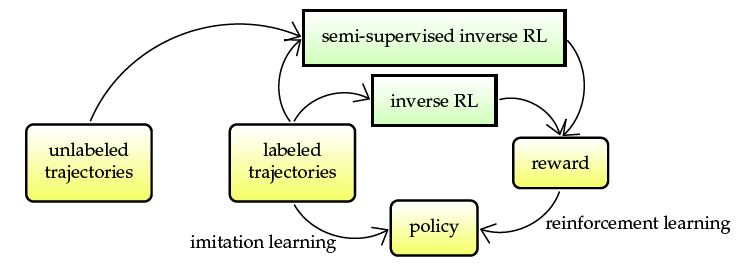
Semi-supervised apprenticeship learning, 2011 - 2015, relevant literature
 with Julien Audiffren, Mohammad Ghavamzadeh, and Alessandro Lazaric
with Julien Audiffren, Mohammad Ghavamzadeh, and Alessandro Lazaric
In apprenticeship learning we aim to learn a good behavior by observing an expert or a set of experts. We assume a setting where the expert is maximizing an unknown true reward function, which is often a linear combination of known state features. We consider a situation when we observe many trajectories of behaviors but only one or a few of them are labeled as experts' trajectories. We investigate the assumptions under which the remaining unlabeled trajectories can aid in learning a policy with a good performance.
[EWRL 2012] [IJCAI 2015] -
Composing Learning for Artificial Cognitive Systems, 2011 - 2015
with Rémi Munos, Mohammad Ghavamzadeh, Alessandro Lazaric, and Daniil Ryabko
 The purpose of this project is to develop a unified toolkit for intelligent control in many different problem areas.
This toolkit will incorporate many of the most successful approaches to a variety of important control problems within a single framework,
including bandit problems, Markov Decision Processes (MDPs), Partially Observable MDPs (POMDPs), continuous stochastic control, and
multi-agent systems.
The purpose of this project is to develop a unified toolkit for intelligent control in many different problem areas.
This toolkit will incorporate many of the most successful approaches to a variety of important control problems within a single framework,
including bandit problems, Markov Decision Processes (MDPs), Partially Observable MDPs (POMDPs), continuous stochastic control, and
multi-agent systems.
[EWRL 2012] [UAI 2013] [ICML 2013] [ICML 2014] [AAAI 2014] [NIPS 2014] [NIPS 2014] [NIPS 2014] -
 Large-scale semi-supervised learning, 2010 - 2013
Large-scale semi-supervised learning, 2010 - 2013
Branislav Kveton, Avneesh Saluja
We parallelized online harmonic solver to process 1 TB of video data in a day. I am working on the multi-manifold learning that can overcome changes in distribution. I am showing how the online learner adapts as to characters' aging over 10 years period in Married ... with Children sitcom. The research was part of Everyday Sensing and Perception (ESP) project.
[FG 2013] -
 Online semi-supervised learning 2009 - 2013
Online semi-supervised learning 2009 - 2013
with Branislav Kveton, Ali Rahimi, Ling Huang, Daniel Ting
We extended graph-based semi-supervised learning to the structured case and demonstrated on handwriting recognition and object detection from video streams. Regularized harmonic function solution: The algorithm outputs a confidence of inference and uses it for learning. We came up with an online algorithm that on the real-world datasets recognizes faces at 80-90% precision with 90% recall.
[UAI 2010] [AISTATS 2010] [CVPR - OLCV 2010]
Past Research Projects
- Anomaly detection in clinical databases, 2007 - 2013
with Miloš Hauskrecht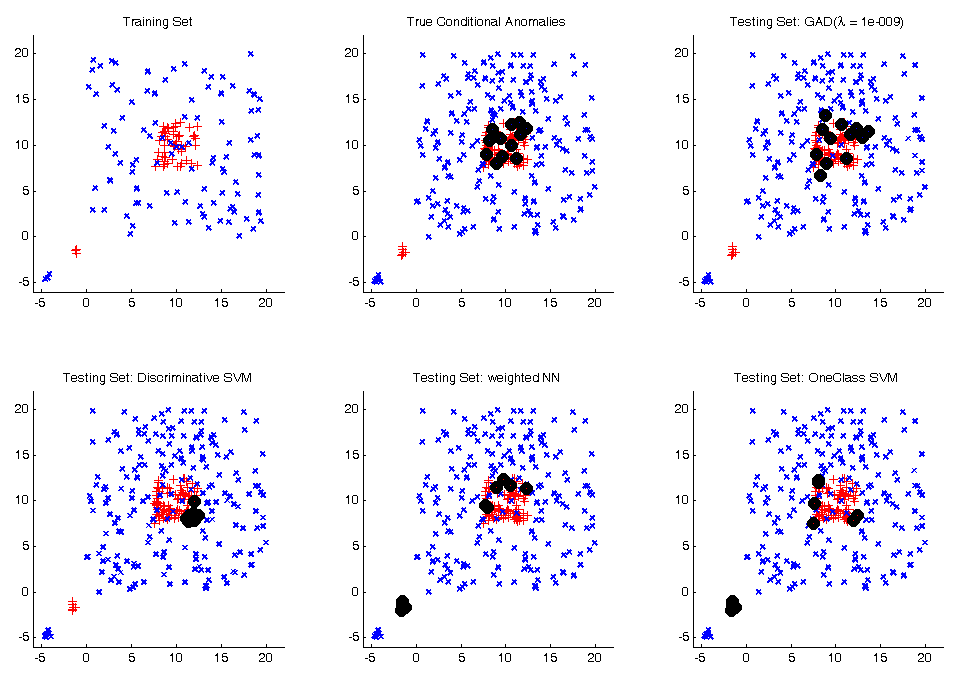
Statistical anomaly detection methods for identification of unusual outcomes and patient management decisions. I combined max-margin learning with distance learned to create and anomaly detector, which outperforms the hospital rule for Heparin Induced Thrombocytopenia detection. I later scaled the system for 5K patients with 9K features and 743 clinical decisions per day. At the recent study, from 222 alerts 50% were highly relevant.
[AMIA 2007] [FLAIRS 2008] [ICML-HEALTH 2008] [MEDINFO 2010] [AMIA 2010] [ICDM 2011] [JBI 2013] - Odd-Man-Out, 2007 - 2011
 with Wendy Chapman,
Roger Day,
Gregory Cooper,
with Wendy Chapman,
Roger Day,
Gregory Cooper,
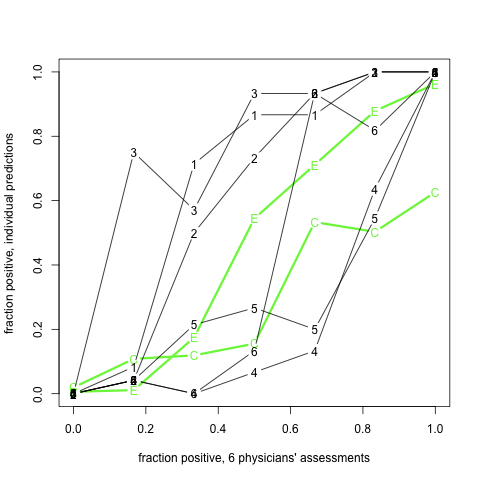
We hypothesized that clinical data in emergency department (ED) reports would increase sensitivity and specificity of case identification for patients with an acute lower respiratory syndrome (ALRS). We designed a statistic of disagreement (odd-man-out) to evalute the machine learning classifier with expert evaluation in the cases when the gold standard is not available.
[ISDS 2006] - High-throughput proteomic and genomic data and biomarker discovery, 2006 - 2007
with Miloš Hauskrecht, Richard Pelikan, Shuguang Wang
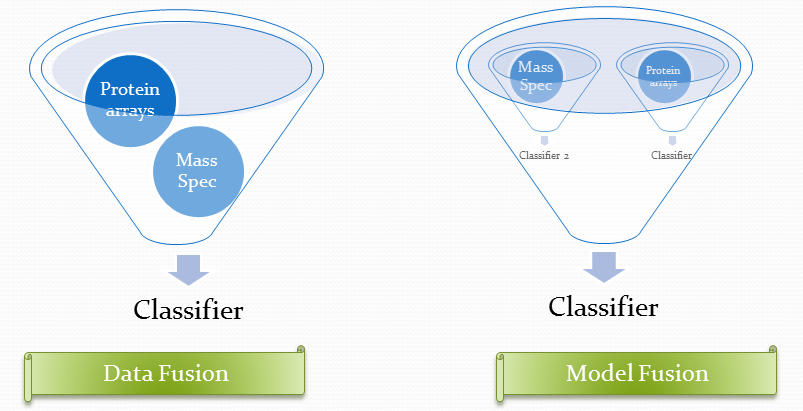 I built a framework for the cancer prediction from high--throughput proteomic and genomic data sources.
I found a way to merge heterogeneous data sources: My fusion model was able to predict
pancreatic cancer from Luminex combined with SELDI with 91.2% accuracy.
I built a framework for the cancer prediction from high--throughput proteomic and genomic data sources.
I found a way to merge heterogeneous data sources: My fusion model was able to predict
pancreatic cancer from Luminex combined with SELDI with 91.2% accuracy.
[Springer 2006] [STB 2008] [IJD 2011] -
 Evolutionary feature selection algorithms, 2005
Evolutionary feature selection algorithms, 2005
with Nuno Miguel Cavalheiro Marques, Marco Castelani
We enhanced the existing FeaSANNT neural feature selection with spiking neuron model to handle inputs noised with up to 10% Gaussian noise.
-
Plastic Synapses (regularity counting), 2003 - 2005
 with Juraj Pavlásek Radoslav Harman, Ján Jenča
with Juraj Pavlásek Radoslav Harman, Ján Jenča
We were modeling basic learning function at the level of synapses. I designed a model that is able to adapt to the regular frequencies with different a rate as the time flows. I used genetic programming to find biologically plausible networks that distinguish different gamma distribution and provided explanation of the strategies evolved.
mv